En una subestación digital con un amplio uso de comunicaciones GOOSE, el personal se topó con la aparición periódica de señales «Fallo» y «Error de GOOSE entrante» de varios dispositivos de protección y SCADA. Estos episodios se producían varias veces al día: el sistema pasaba de repente a un estado de fallo y luego regresaba por sí solo al funcionamiento normal. La causa de lo que ocurría, sin embargo, seguía sin estar clara.
Externamente, el sistema seguía funcionando con normalidad:
- no se producían disparos de equipos;
- no se registraban faltas;
- no se perdía la comunicación con los dispositivos;
- la autodiagnosis de los IEDs no mostraba fallos.
Son precisamente estos problemas «flotantes» los que se consideran de los más difíciles de investigar en una subestación digital. Una dificultad adicional era la ausencia, en la instalación, de un sistema de monitoreo en línea según IEC 61850, que podría haber registrado y clasificado automáticamente los eventos anómalos en la red local del objeto.
La única fuente de información resultó ser un archivo pcap de unos 11 minutos, registrado por los especialistas al conectarse a la LAN de la subestación. A partir de esa captura había que entender qué estaba ocurriendo con los dispositivos de protección y SCADA.
Por qué Wireshark no es suficiente
Los especialistas comenzaron el análisis inicial en Wireshark. Es la herramienta más popular para trabajar con tráfico de red y resulta excelente para la inspección detallada de paquetes individuales. Sin embargo, en incidentes como este el problema no está en la falta de acceso a los datos, sino en la escala y la complejidad del propio análisis.
Los ingenieros disponían de un archivo pcap con casi 186 mil paquetes GOOSE y más de 200 fuentes GOOSE activas. Con ese volumen de tráfico, el especialista ve un flujo continuo de mensajes, dentro del cual hay que encontrar desviaciones de corta duración.
La dificultad está también en que, para el análisis manual, el ingeniero debe saber de antemano qué y dónde buscar exactamente: la desaparición de GOOSE en la red o el cambio de calidad de las señales, retardos de GOOSE o un problema de sincronización de tiempo en los dispositivos, etc. Como resultado, la búsqueda de la causa se convierte en la comprobación de decenas de hipótesis entre miles de paquetes.
Por ejemplo, para detectar una superación de corta duración del parámetro timeAllowedToLive (TATL) hay que analizar manualmente los intervalos entre paquetes adyacentes de cada mensaje GOOSE y compararlos con el valor de TATL transmitido en el mensaje anterior. Con ese volumen de tráfico, tal comprobación puede llevar horas, sobre todo si la violación dura apenas unas decenas de milisegundos.
No menos difícil es el análisis de la calidad de las señales GOOSE. Una sola publicación puede transmitir decenas de señales, y el cambio de un solo bit de calidad — por ejemplo, la transición de validity a Invalid — queda oculto dentro de la estructura GOOSE y es extremadamente difícil de detectar visualmente.
En teoría, todos estos problemas pueden descubrirse con Wireshark. En la práctica, tal análisis requiere muchas horas de trabajo manual y, aun así, no garantiza que la causa del incidente se encuentre realmente.
La solución: análisis automático de pcap en Tekvel Magic
El archivo pcap se cargó en el software Tekvel Magic — el análisis llevó unos minutos. Tras el procesamiento, el programa generó automáticamente un informe Excel que reunió todos los dispositivos, eventos y violaciones problemáticos detectados, con indicación del nivel de criticidad.
Cada evento se vincula a un número de paquete concreto en el archivo pcap. Si es necesario, el ingeniero puede abrir el punto correspondiente en Wireshark sabiendo ya exactamente qué ocurrió. Además, si se dispone de un archivo SCD as-built correspondiente a la configuración de los dispositivos, en lugar del número de orden de la señal se indica la señal del modelo y su descripción — lo que facilita mucho la comprensión de la situación.
Lo principal es que los ingenieros ya no tenían que buscar el problema a mano entre miles de paquetes. En lugar de un gran archivo pcap, obtuvieron una imagen clara de lo que estaba ocurriendo en el objeto.
Del tráfico de red a un informe técnico listo
El resultado del trabajo de Tekvel Magic es un informe completo de verificación extraordinaria. El informe se genera en formato Excel y está construido según el principio de una investigación secuencial — desde una evaluación general del estado de los equipos y de la LAN hasta el análisis detallado de eventos y señales concretos.
La primera página es el «RESUMEN». En ella se muestra la información general sobre el archivo: la hora del registro, un código único del archivo que excluye la posibilidad de manipular el pcap, el número de paquetes y publicaciones GOOSE y SV, así como la conclusión final del análisis — todos los dispositivos, eventos y violaciones problemáticos detectados, con indicación del nivel de criticidad.
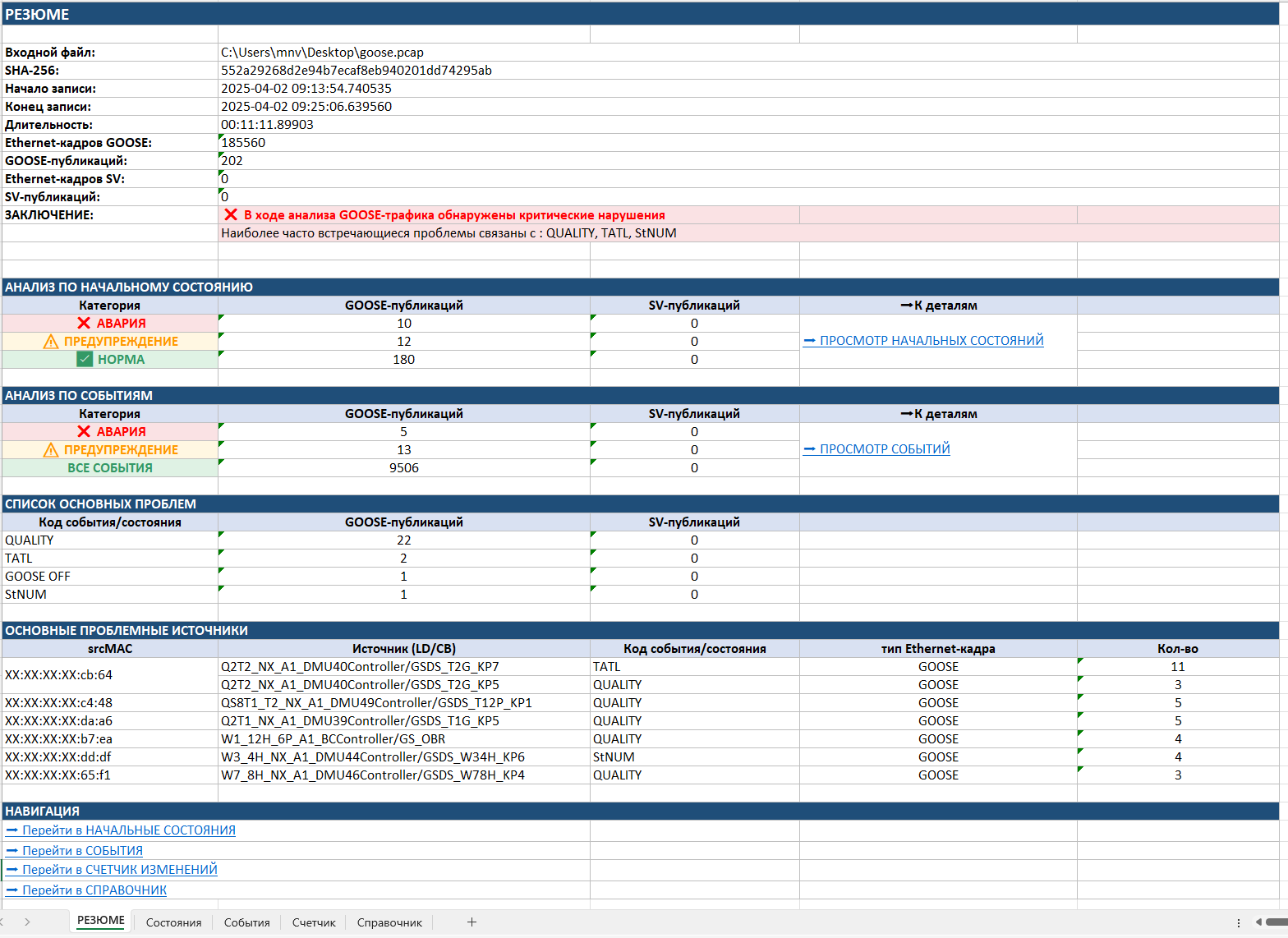
Ya en esta etapa el especialista ve si se detectaron violaciones críticas, cuántas publicaciones GOOSE están en estado de avería, cuántas requieren atención y qué problemas se dan con más frecuencia. Para acelerar la búsqueda de causas, se generan además una lista de los dispositivos-fuente más problemáticos y una relación de los principales tipos de violación. De hecho, el «RESUMEN» permite responder en pocos segundos: ¿hay un problema en la red y dónde buscarlo primero?
La siguiente etapa de la investigación es «Estados». En ella se muestra el estado de todas las publicaciones en el momento en que comenzó el registro del tráfico. La práctica demuestra que muchos problemas existen incluso antes de que el personal inicie la investigación.
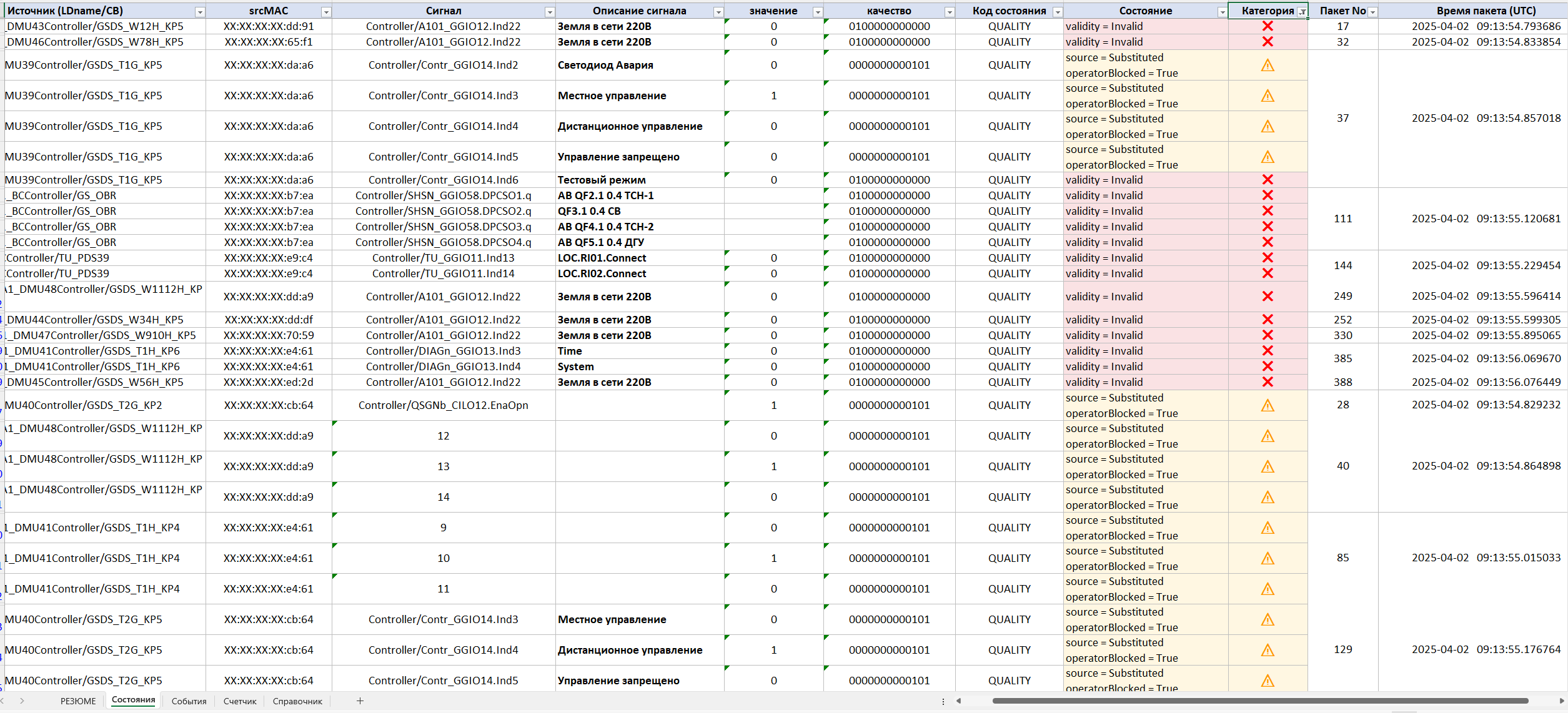
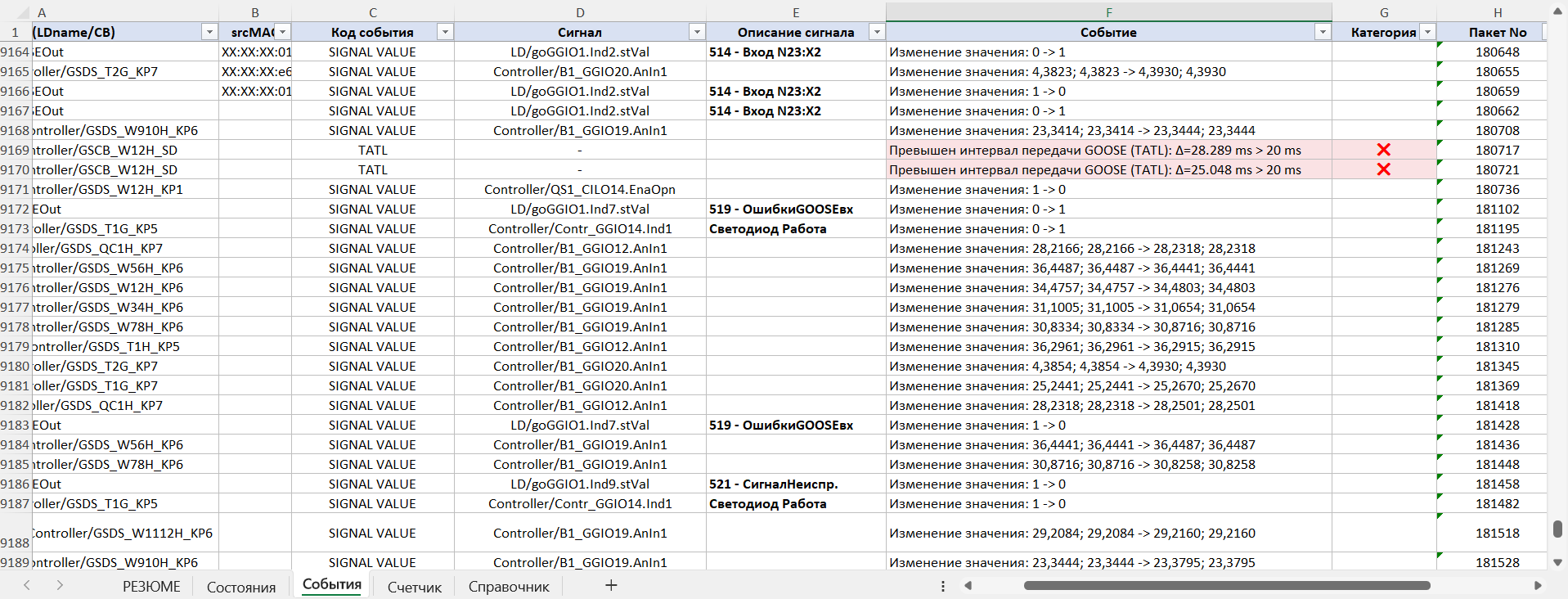
Tras evaluar el estado inicial, el ingeniero pasa a la sección «Eventos», que es la principal herramienta de investigación. Aquí, en orden cronológico, se muestran todos los cambios en los datos y su categorización por criticidad. Para cada evento se indican:
- la fuente (LD/CB);
- el srcMAC del dispositivo;
- la señal;
- la descripción de la violación;
- la categoría de criticidad por su impacto en el funcionamiento de los sistemas de protección y SCADA;
- el número de paquete;
- el instante exacto de aparición.
Gracias a esto, el especialista puede ver el hecho mismo de la violación:
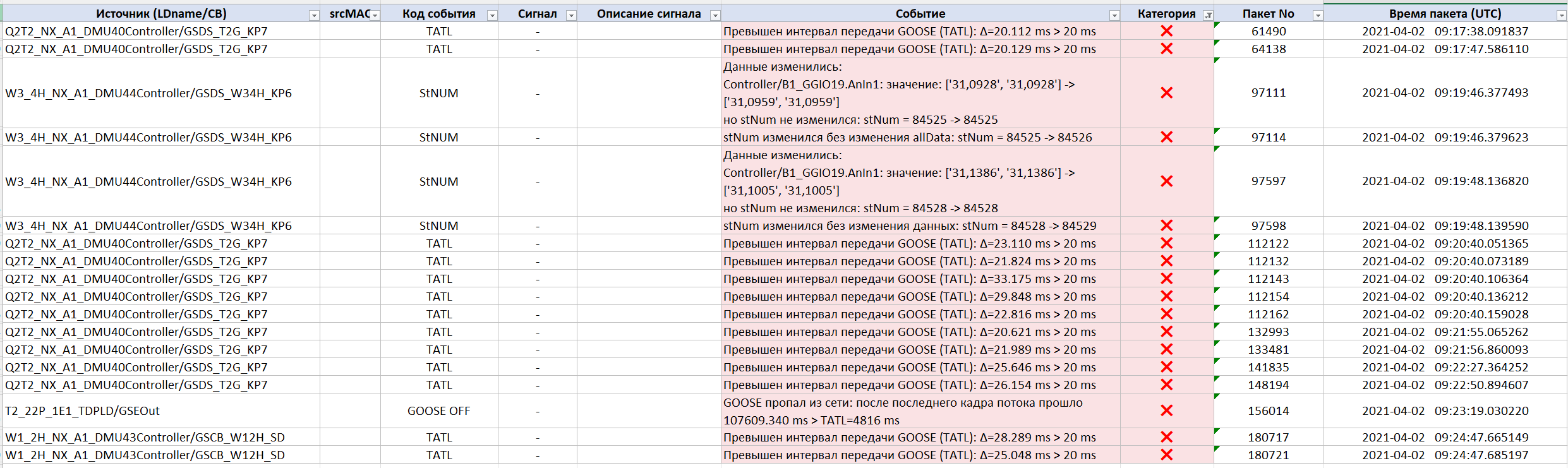
…y seguir la secuencia de eventos que condujo a la aparición del problema en el objeto:
La sección siguiente es el «Contador de cambios». Muestra qué señales cambiaron con mayor frecuencia durante el registro. Para cada señal se calcula el número de cambios y su frecuencia media de aparición en una ventana deslizante de 1 segundo. Este tipo de análisis permite detectar con rapidez cambios inmotivados y/o excesivamente frecuentes del estado de las señales, una banda muerta mal configurada y otros procesos capaces de crear una carga elevada sobre los equipos de la LAN y sobre los propios dispositivos de protección y SCADA.
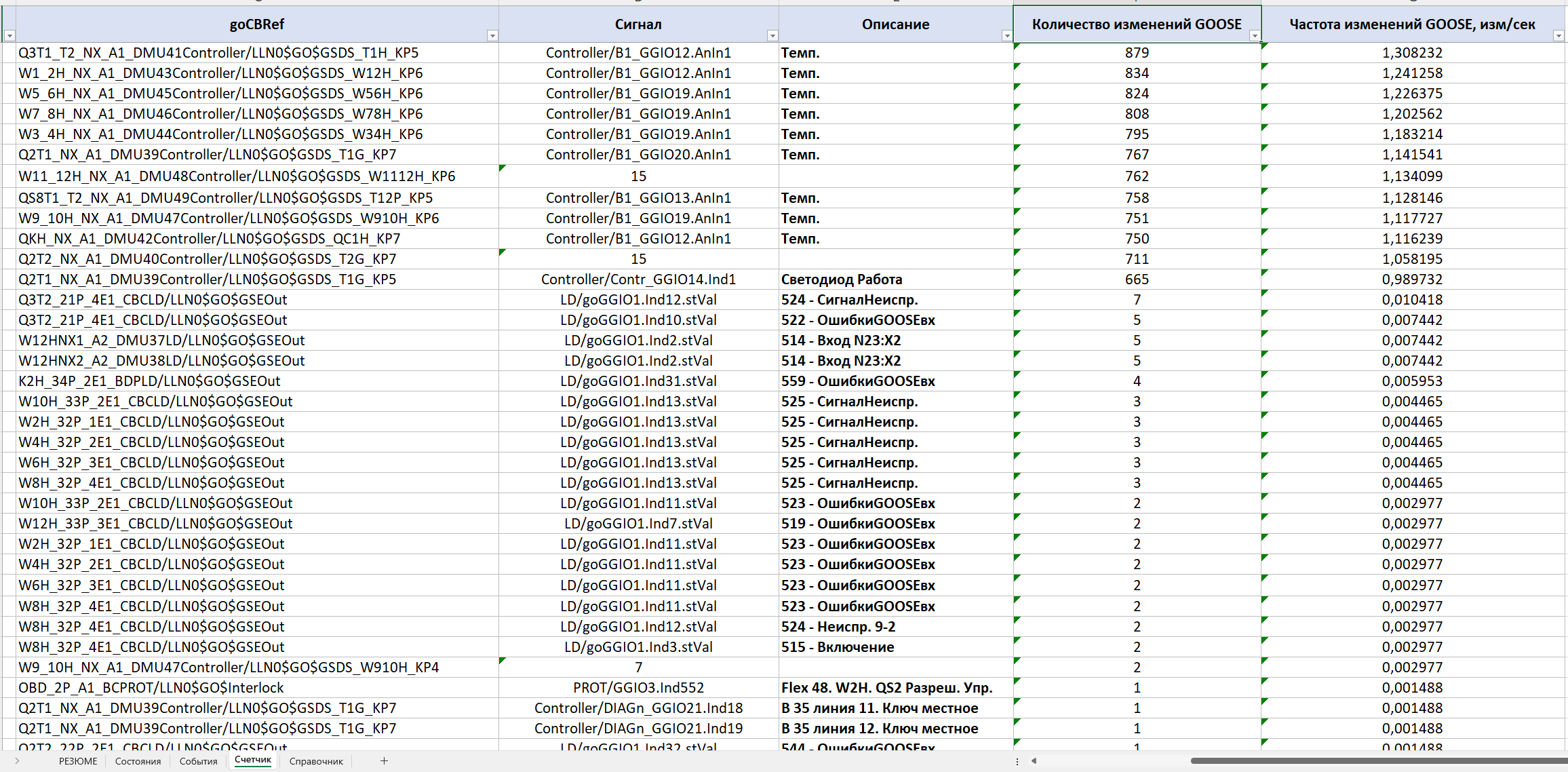
En el ejemplo considerado, fue precisamente esta sección la que permitió ver las señales que cambiaron 600–800 veces en los 11 minutos de registro y que, en la práctica, generaron el grueso del tráfico de eventos.
La última hoja es el «Glosario». Contiene la descripción de todos los criterios de análisis monitorizados, los códigos de evento, las reglas de clasificación de las violaciones y explicaciones de a qué puede conducir cada violación detectada. Gracias a esto, el informe sigue siendo comprensible no solo para el especialista que realizó el análisis, sino también para colegas, fabricantes de equipos o representantes de la organización operadora.
De este modo, Tekvel Magic convierte un archivo pcap en una investigación estructurada del incidente. El ingeniero obtiene una imagen general de lo que ocurre, una lista de dispositivos problemáticos, la cronología completa de los eventos y la posibilidad de ir a un paquete concreto en el volcado de tráfico original si se necesita una comprobación adicional.
Qué se encontró en el objeto
Superaciones críticas de TATL
La causa principal de los «Fallos» cíclicos resultó estar relacionada con una violación del parámetro timeAllowedToLive (TATL). Para uno de los flujos GOOSE, el sistema registró superaciones regulares del intervalo permitido entre paquetes: con TATL = 20 ms, los intervalos reales alcanzaban periódicamente 33 ms. En uno de los episodios se produjeron cinco violaciones consecutivas seguidas — para los dispositivos receptores, esto significó la interrupción de la recepción de información del dispositivo-fuente.
Desaparición completa de un mensaje GOOSE
Además, Tekvel Magic detectó un evento en el que uno de los flujos GOOSE desapareció por completo de la red durante casi dos minutos:
- ausencia de GOOSE — más de 107 segundos;
- intervalo permitido por TATL — 4816 ms.
En la revisión manual en Wireshark, un episodio así es prácticamente imposible de advertir entre cientos de publicaciones activas.
Fallos en el funcionamiento del contador GOOSE stNum
El sistema también detectó un funcionamiento incorrecto del contador de estado stNum:
- los datos del mensaje GOOSE cambiaron, pero stNum no se incrementó;
- luego stNum se incrementó sin que cambiaran los datos.
Es un indicio de comportamiento anómalo de la publicación GOOSE, capaz de provocar una interpretación incorrecta de los eventos por parte de los dispositivos receptores.
Problemas de calidad de los datos
En varias publicaciones se encontró el atributo validity = Invalid. Además, parte de las violaciones ya estaba presente en el estado inicial del registro — es decir, el problema existía incluso antes del momento que los especialistas consideraban el inicio de la verificación extraordinaria.
Conclusiones
El fallo «flotante», difícil de localizar con las herramientas habituales, resultó ser no un único error, sino todo un conjunto de violaciones interrelacionadas en el tráfico GOOSE: superaciones periódicas de TATL, desapariciones cortas y prolongadas de publicaciones, fallos del contador stNum y degradación de la calidad de las señales. Cada una de estas violaciones, por separado, es corta en el tiempo y se pierde fácilmente en el flujo general — y es justamente por eso que el análisis manual en Wireshark no daba resultado.
Con el software Tekvel Magic, convertir la captura de 11 minutos en un informe estructurado llevó un par de minutos, en lugar de muchas horas de trabajo manual — y aun así dio un resultado que el análisis manual no garantizaba.
Conviene subrayar aparte una lección sistémica: la ausencia de monitoreo permanente (un sistema de monitoreo en línea según IEC 61850) en el objeto convierte cualquier incidente en una investigación «de campo» puntual, basada en una captura registrada por casualidad. Allí donde tal sistema está instalado, eventos como las superaciones de TATL, las desapariciones de GOOSE y los fallos de stNum se registran y clasifican de forma continua — y la mayoría de los fallos «flotantes» dejan de ser un misterio. Pero incluso cuando no hay monitoreo continuo, el software Tekvel Magic permite realizar una investigación completa a posteriori: cargar el pcap, obtener un informe técnico y tomar una decisión de ingeniería fundamentada.
Magia de verdad — pero totalmente de ingeniería.