Sur un poste numérique faisant un large usage des communications GOOSE, le personnel a été confronté à l'apparition périodique des signaux « Défaut » et « Erreur de GOOSE entrant » provenant de plusieurs équipements de protection et SCADA. Ces épisodes se produisaient plusieurs fois par jour : le système basculait soudain dans un état de défaut, puis revenait de lui-même au fonctionnement normal. La cause de ces phénomènes, cependant, restait obscure.
Extérieurement, le système continuait de fonctionner normalement :
- aucun déclenchement d'équipement ne se produisait ;
- aucun défaut n'était enregistré ;
- la liaison avec les équipements n'était pas perdue ;
- l'autodiagnostic des IED ne signalait aucune défaillance.
Ce sont précisément ces problèmes « flottants » qui comptent parmi les plus difficiles à investiguer sur un poste numérique. Une difficulté supplémentaire tenait à l'absence, sur le site, d'un système de supervision en ligne selon l'IEC 61850, qui aurait pu enregistrer et classer automatiquement les événements anormaux sur le réseau local de l'ouvrage.
La seule source d'information s'est avérée être un fichier pcap d'environ 11 minutes, enregistré par les spécialistes lors d'un raccordement au LAN du poste. C'est à partir de cette capture qu'il fallait comprendre ce qui se passait avec les équipements de protection et SCADA.
Pourquoi Wireshark ne suffit pas
Les spécialistes ont commencé l'analyse initiale sous Wireshark. C'est l'outil le plus répandu pour travailler avec le trafic réseau, et il est excellent pour l'inspection détaillée de trames individuelles. Dans ce type d'incidents, toutefois, le problème ne tient pas à un défaut d'accès aux données, mais à l'ampleur et à la complexité de l'analyse elle-même.
Les ingénieurs disposaient d'un fichier pcap comportant près de 186 000 trames GOOSE et plus de 200 sources GOOSE actives. À ce volume de trafic, le spécialiste voit un flux continu de messages, à l'intérieur duquel il faut trouver des écarts de courte durée.
La difficulté tient aussi à ce que, pour une analyse manuelle, l'ingénieur doit savoir à l'avance précisément quoi chercher et où : une disparition de GOOSE sur le réseau ou un changement de qualité des signaux, des retards de GOOSE ou un problème de synchronisation temporelle sur les équipements, etc. En conséquence, la recherche de la cause se transforme en vérification de dizaines d'hypothèses parmi des milliers de trames.
Par exemple, pour détecter un dépassement de courte durée du paramètre timeAllowedToLive (TATL), il faut analyser manuellement les intervalles entre trames adjacentes de chaque message GOOSE et les comparer à la valeur de TATL transmise dans le message précédent. À ce volume de trafic, une telle vérification peut prendre des heures, surtout si la violation ne dure que quelques dizaines de millisecondes.
L'analyse de la qualité des signaux GOOSE n'est pas moins difficile. Une seule publication peut transporter des dizaines de signaux, et le changement ne serait-ce que d'un seul bit de qualité — par exemple le passage de validity à Invalid — est masqué à l'intérieur de la structure GOOSE et extrêmement difficile à repérer visuellement.
En théorie, tous ces problèmes peuvent être mis en évidence avec Wireshark. En pratique, une telle analyse exige de nombreuses heures de travail manuel et ne garantit pas pour autant que la cause de l'incident sera réellement trouvée.
La solution : analyse automatique du pcap dans Tekvel Magic
Le fichier pcap a été chargé dans le logiciel Tekvel Magic — l'analyse a pris quelques minutes. Après traitement, le programme a automatiquement produit un rapport Excel rassemblant tous les équipements, événements et violations problématiques détectés, avec l'indication du niveau de criticité.
Chaque événement est rattaché à un numéro de trame précis dans le fichier pcap. Si nécessaire, l'ingénieur peut ouvrir l'endroit voulu dans Wireshark en sachant déjà exactement ce qui s'est produit. De plus, si un fichier SCD as-built correspondant à la configuration des équipements est disponible, au lieu du numéro d'ordre du signal le rapport indique le signal du modèle et sa description — ce qui facilite grandement la compréhension de la situation.
L'essentiel est que les ingénieurs n'avaient plus à chercher le problème à la main parmi des milliers de trames. Au lieu d'un volumineux fichier pcap, ils ont obtenu une image claire de ce qui se passait sur l'ouvrage.
Du trafic réseau à un rapport technique prêt à l'emploi
Le résultat du travail de Tekvel Magic est un rapport complet de vérification exceptionnelle. Le rapport est généré au format Excel et construit selon le principe d'une investigation séquentielle — de l'évaluation générale de l'état des équipements et du LAN à l'analyse détaillée d'événements et de signaux précis.
La première page est le « RÉSUMÉ ». On y trouve les informations générales sur le fichier : l'heure d'enregistrement, un code unique du fichier excluant toute altération du pcap, le nombre de trames et de publications GOOSE et SV, ainsi que la conclusion finale de l'analyse — tous les équipements, événements et violations problématiques détectés, avec l'indication du niveau de criticité.
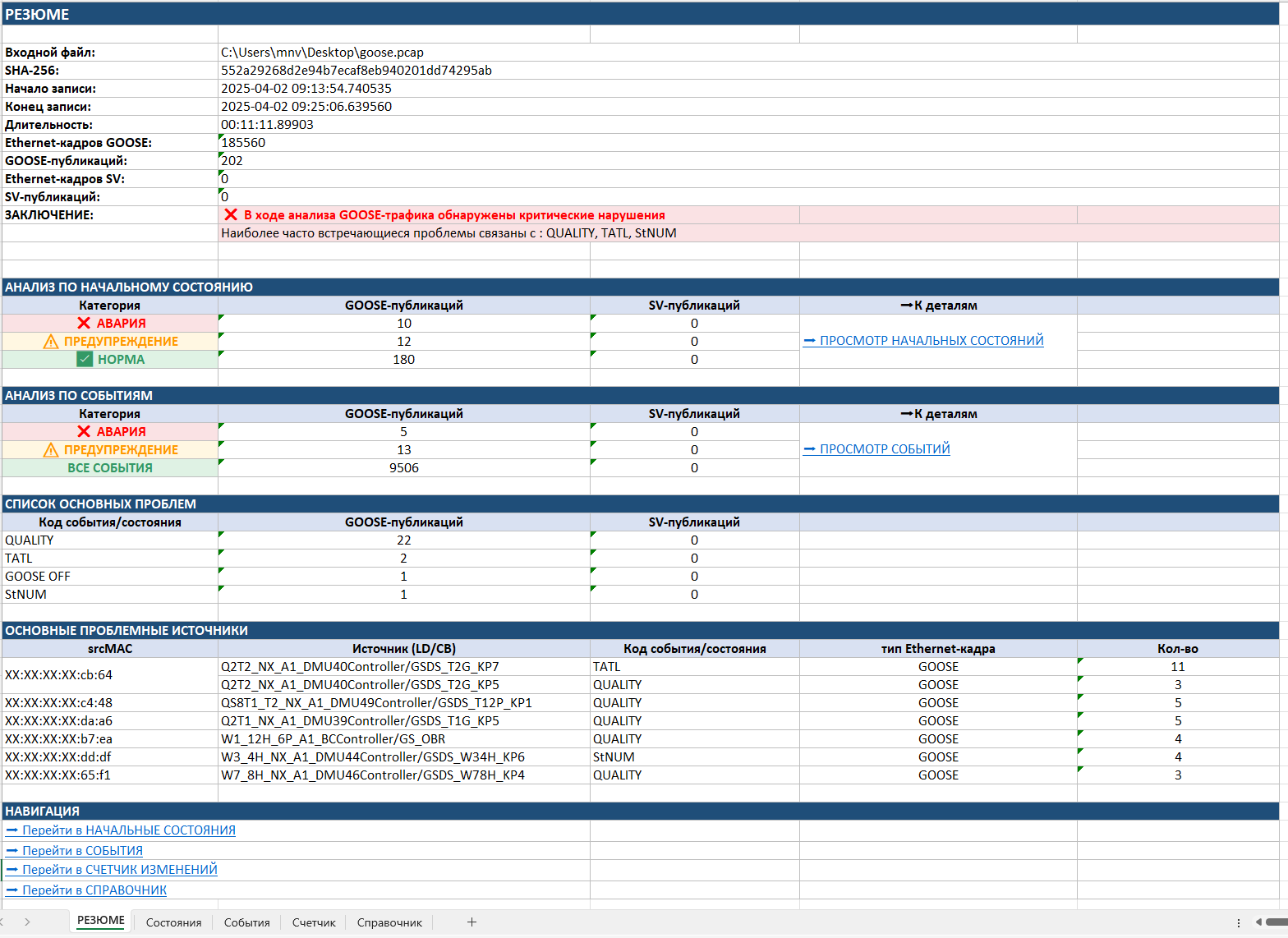
Dès cette étape, le spécialiste voit si des violations critiques ont été détectées, combien de publications GOOSE sont en état d'avarie, combien requièrent une attention et quels problèmes reviennent le plus souvent. Pour accélérer la recherche des causes, une liste des équipements-sources les plus problématiques et une liste des principaux types de violation sont également produites. De fait, le « RÉSUMÉ » permet de répondre en quelques secondes : y a-t-il un problème sur le réseau et où le chercher en premier ?
L'étape suivante de l'investigation est « États ». Elle affiche l'état de toutes les publications au moment où l'enregistrement du trafic a commencé. La pratique montre que de nombreux problèmes existent avant même que le personnel ne commence l'investigation.
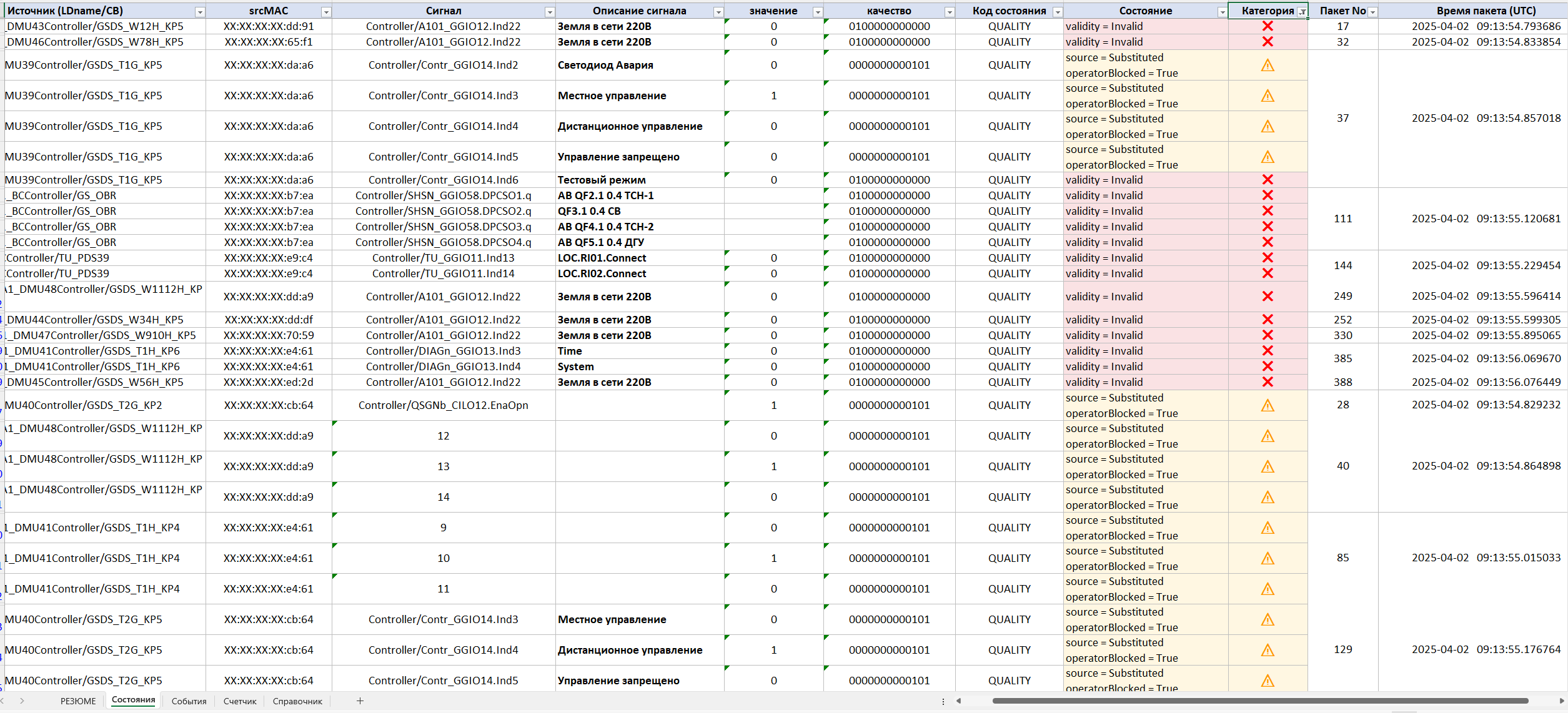
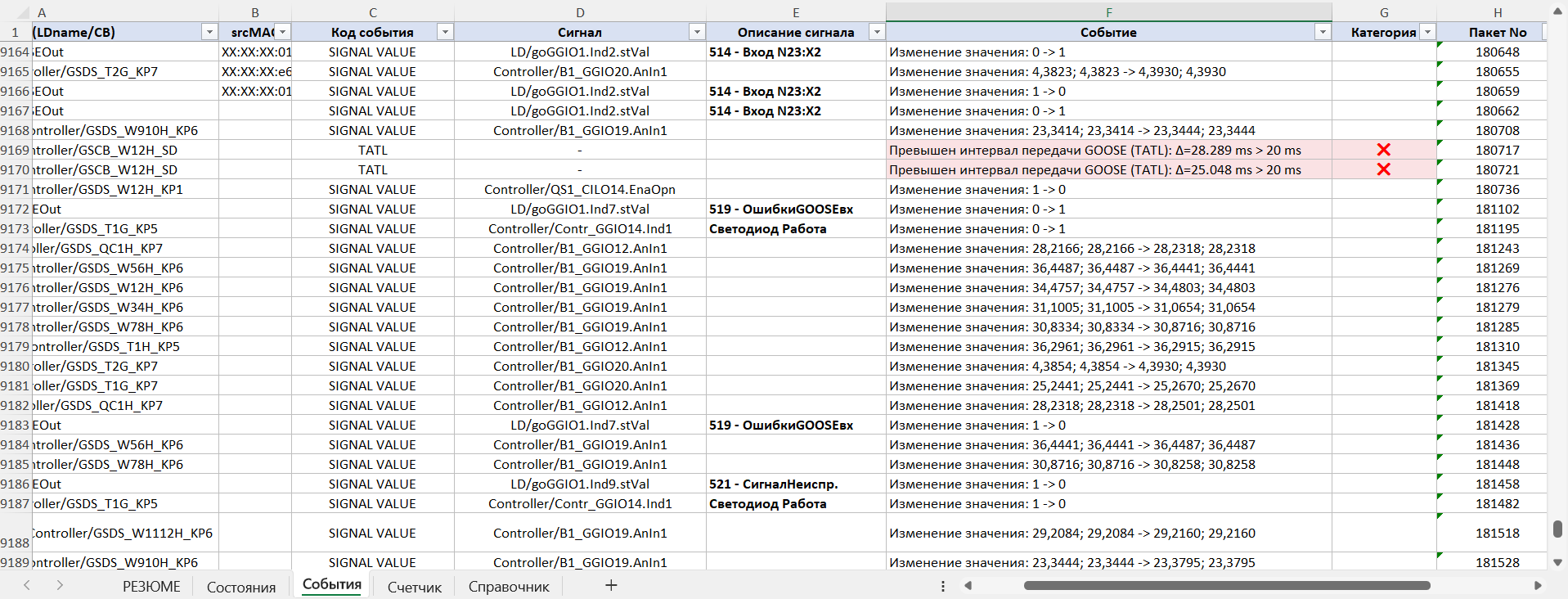
Après l'évaluation de l'état initial, l'ingénieur passe à la section « Événements », qui est le principal outil d'investigation. Y figurent, dans l'ordre chronologique, tous les changements dans les données et leur catégorisation par criticité. Pour chaque événement sont indiqués :
- la source (LD/CB) ;
- le srcMAC de l'équipement ;
- le signal ;
- la description de la violation ;
- la catégorie de criticité selon son impact sur le fonctionnement des systèmes de protection et SCADA ;
- le numéro de trame ;
- l'instant exact d'apparition.
Grâce à cela, le spécialiste peut voir le fait même de la violation :
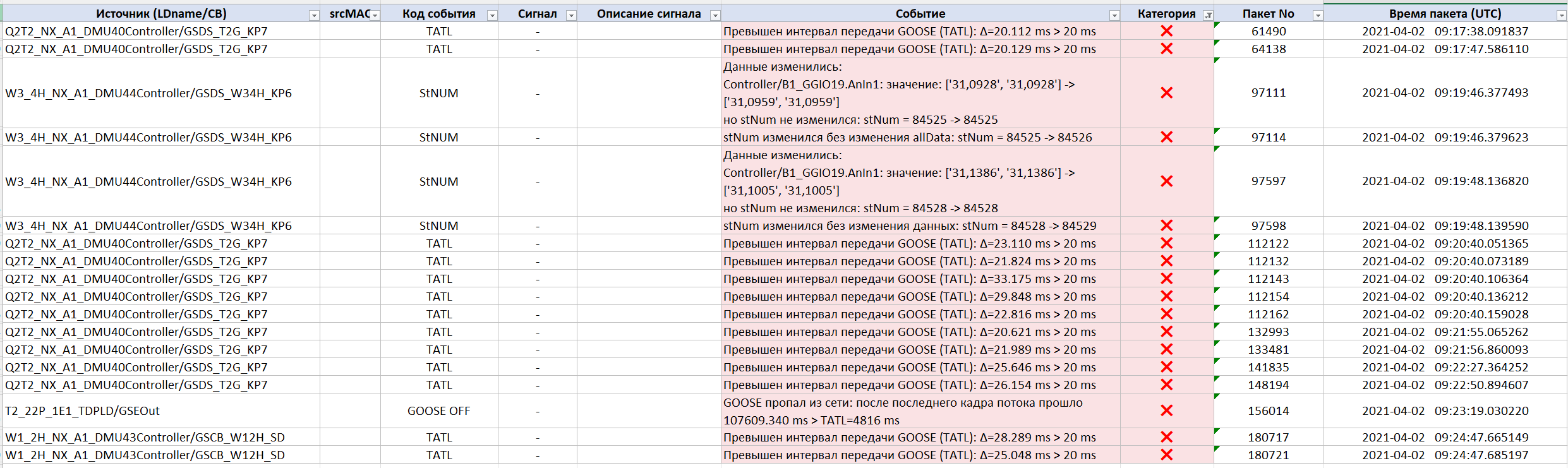
…et suivre la séquence d'événements qui a conduit à l'apparition du problème sur l'ouvrage :
La section suivante est le « Compteur de changements ». Il indique quels signaux ont changé le plus souvent pendant l'enregistrement. Pour chaque signal sont calculés le nombre de changements et leur fréquence moyenne d'apparition dans une fenêtre glissante d'une seconde. Ce type d'analyse permet de détecter rapidement des changements injustifiés et/ou excessivement fréquents de l'état des signaux, une bande morte mal configurée et d'autres processus susceptibles d'imposer une charge accrue aux équipements du LAN et aux équipements de protection et SCADA eux-mêmes.
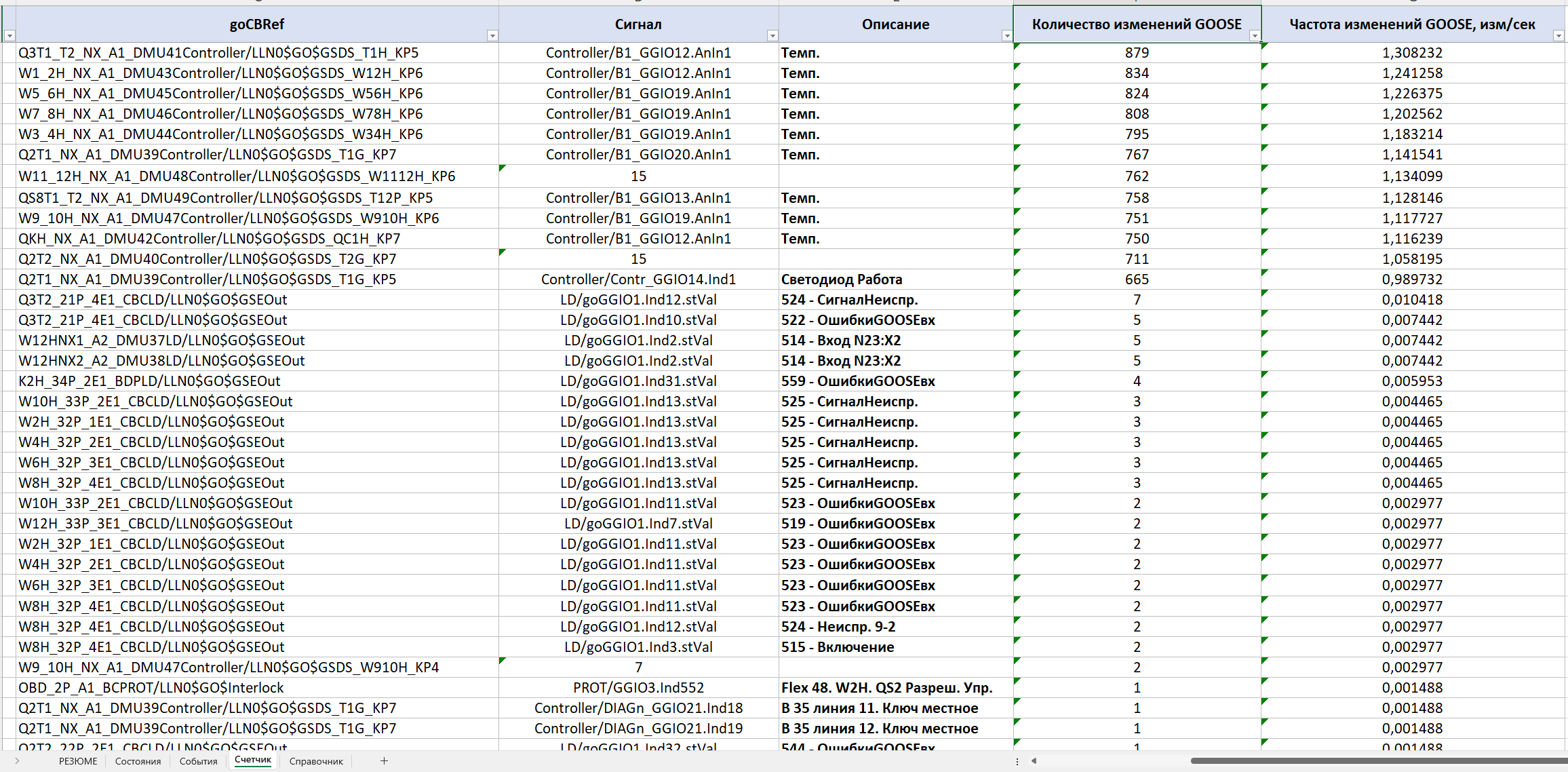
Dans l'exemple considéré, c'est précisément cette section qui a permis de repérer les signaux ayant changé 600 à 800 fois pendant les 11 minutes d'enregistrement et qui, en pratique, ont généré l'essentiel du trafic d'événements.
Le dernier onglet est le « Glossaire ». Il contient la description de tous les critères d'analyse surveillés, des codes d'événement, des règles de classification des violations et des explications sur ce à quoi chaque violation détectée peut conduire. Grâce à cela, le rapport reste compréhensible non seulement pour le spécialiste qui a réalisé l'analyse, mais aussi pour des collègues, des fabricants d'équipements ou des représentants de l'organisation exploitante.
Ainsi, Tekvel Magic transforme un fichier pcap en une investigation structurée de l'incident. L'ingénieur obtient une image globale de ce qui se passe, une liste des équipements problématiques, la chronologie complète des événements et la possibilité d'accéder à une trame précise dans le dump de trafic d'origine si une vérification complémentaire est nécessaire.
Ce qui a été découvert sur l'ouvrage
Dépassements critiques de TATL
La cause principale des « Défauts » cycliques s'est avérée liée à une violation du paramètre timeAllowedToLive (TATL). Pour l'un des flux GOOSE, le système a enregistré des dépassements réguliers de l'intervalle autorisé entre trames : avec TATL = 20 ms, les intervalles réels atteignaient périodiquement 33 ms. Lors de l'un des épisodes, cinq violations consécutives se sont produites d'affilée — pour les équipements récepteurs, cela signifiait l'arrêt de la réception des informations en provenance de l'équipement source.
Disparition complète d'un message GOOSE
De plus, Tekvel Magic a détecté un événement où l'un des flux GOOSE a complètement disparu du réseau pendant près de deux minutes :
- absence de GOOSE — plus de 107 secondes ;
- intervalle autorisé par TATL — 4816 ms.
Lors d'un examen manuel sous Wireshark, un tel épisode est pratiquement impossible à remarquer parmi des centaines de publications actives.
Dysfonctionnements du compteur GOOSE stNum
Le système a également mis en évidence un fonctionnement incorrect du compteur d'état stNum :
- les données du message GOOSE ont changé, mais stNum n'a pas été incrémenté ;
- puis stNum a été incrémenté sans aucun changement des données.
C'est un signe de comportement anormal de la publication GOOSE, susceptible d'entraîner une interprétation erronée des événements par les équipements récepteurs.
Problèmes de qualité des données
Dans plusieurs publications, l'attribut validity = Invalid a été détecté. De plus, une partie des violations était déjà présente dans l'état initial de l'enregistrement — autrement dit, le problème existait avant même le moment que les spécialistes considéraient comme le début de la vérification exceptionnelle.
Conclusions
Le défaut « flottant », difficile à localiser avec les outils habituels, s'est révélé être non pas une erreur unique, mais tout un ensemble de violations interdépendantes du trafic GOOSE : dépassements périodiques de TATL, disparitions courtes et prolongées de publications, dysfonctionnements du compteur stNum et dégradation de la qualité des signaux. Chacune de ces violations, prise isolément, est brève dans le temps et se perd aisément dans le flux général — et c'est précisément pour cela que l'analyse manuelle sous Wireshark ne donnait pas de résultat.
Avec le logiciel Tekvel Magic, transformer la capture de 11 minutes en un rapport structuré a pris quelques minutes au lieu de nombreuses heures de travail manuel — et a tout de même fourni un résultat que l'analyse manuelle ne garantissait pas.
Il convient de souligner à part une leçon systémique : l'absence de supervision permanente (un système de supervision en ligne selon l'IEC 61850) sur le site transforme tout incident en une investigation « de terrain » ponctuelle, fondée sur une capture enregistrée par hasard. Là où un tel système est installé, des événements comme les dépassements de TATL, les disparitions de GOOSE et les dysfonctionnements de stNum sont enregistrés et classés en continu — et la plupart des défauts « flottants » cessent d'être une énigme. Mais même en l'absence de supervision continue, le logiciel Tekvel Magic permet de mener une investigation complète a posteriori : charger le pcap, obtenir un rapport technique et prendre une décision d'ingénierie éclairée.
De la vraie magie — mais entièrement d'ingénierie.